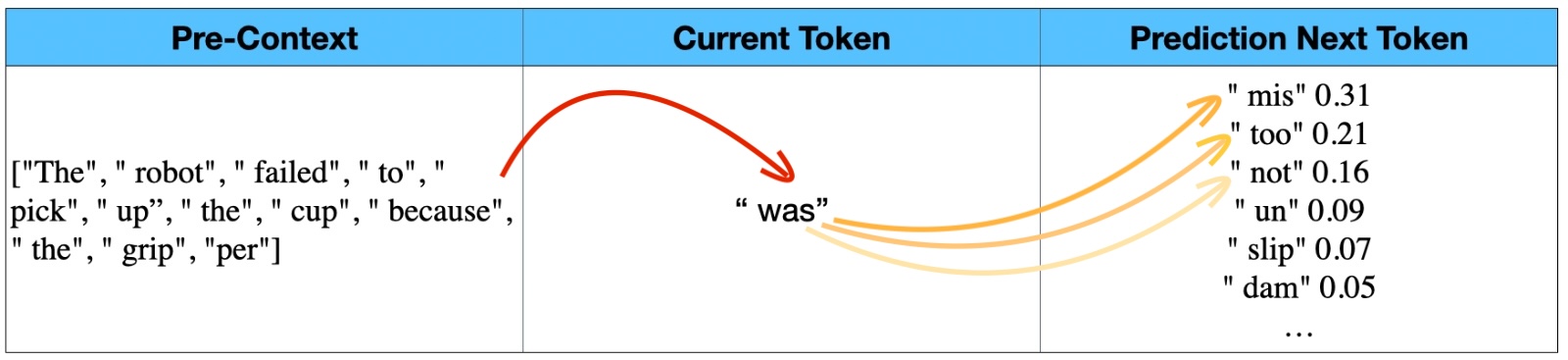
Language Models
Predict the next token
The model uses prior context plus the current token to estimate what word piece comes next.

The data brick to scale the next generation of embodied AI
Teraturn is built to help robots operate in complex human environments.
A real-world dataset for navigation, interaction, and action.
Real-World Data Infrastructure
Our smart-glasses platform is already built. We are now focused on deploying it with real contributors to capture high-quality action data from everyday human environments.
Upload a short POV video. We sample a few moments and return a preview JSON.
Best for short POV clips longer than 5 seconds.
Waiting for upload…
Preview only. Models can make mistakes.
Upload a video to generate a sample JSON output…
Same idea, different output: language models predict the next token, while embodied AI must predict the next physical action.
Language Models
The model uses prior context plus the current token to estimate what word piece comes next.
Embodied AI
The system uses prior context plus the current action to estimate what physical behavior should happen next.
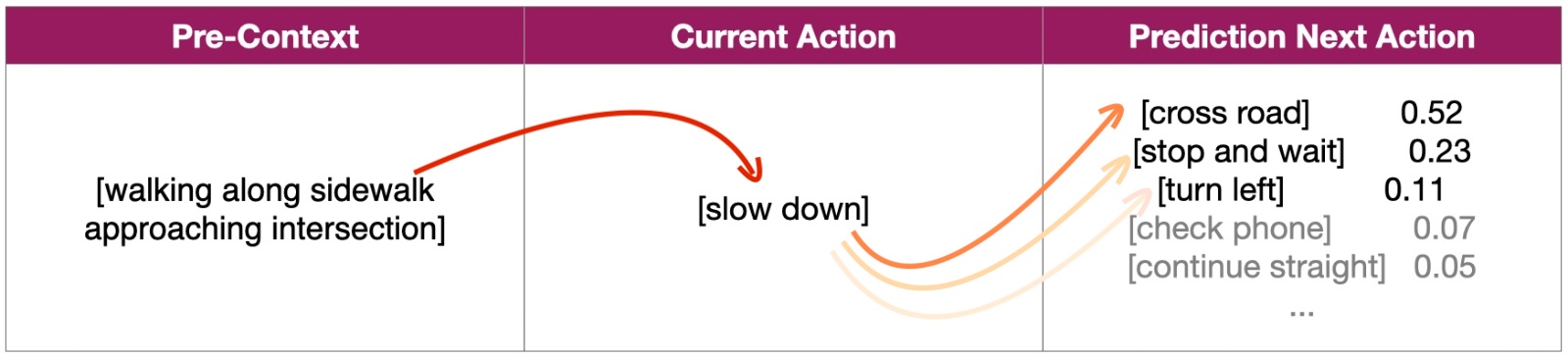
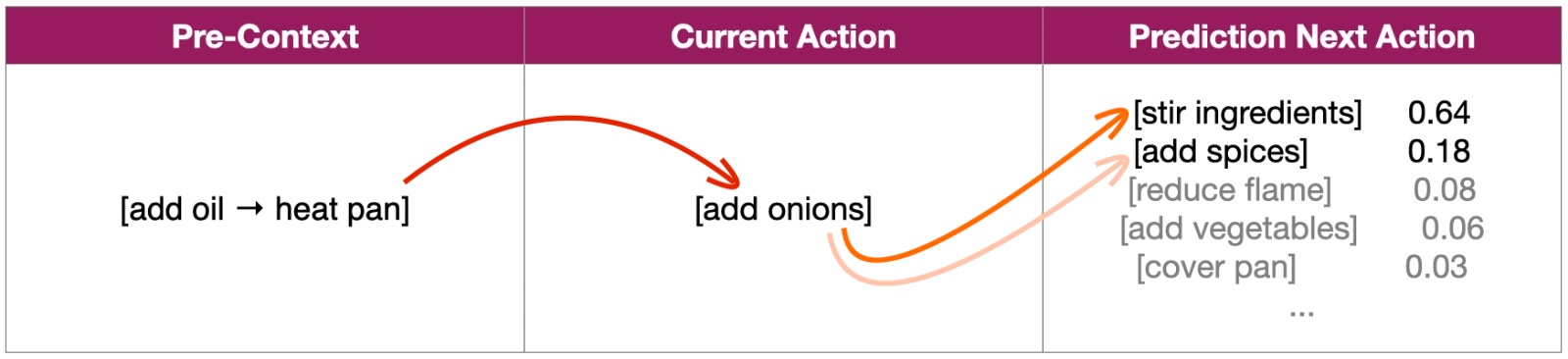
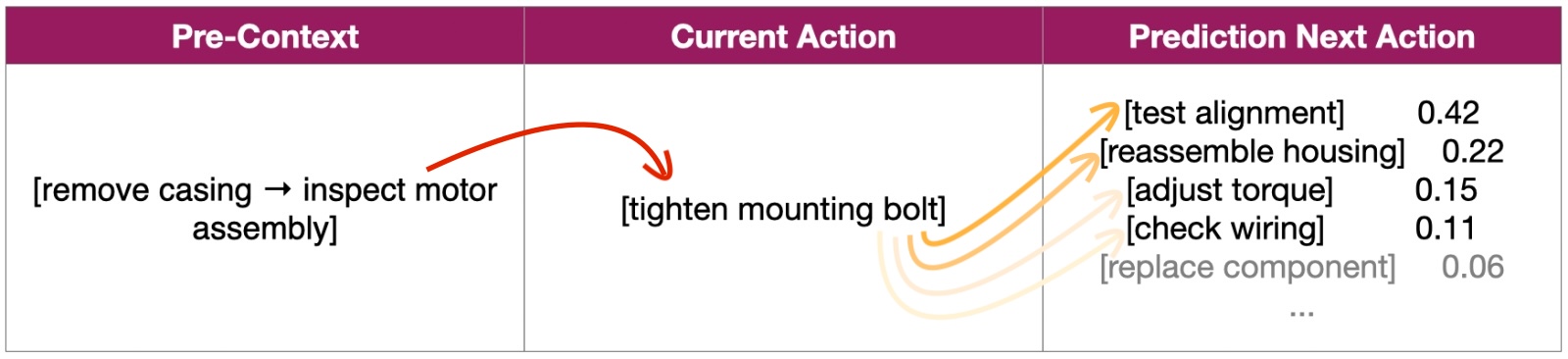
Real-world first-person data is the missing layer that helps models move from understanding language to understanding behavior.
How Teraturn Gets Built
We focus on authentic environments, scalable capture, and deployment operations that work outside the lab.
01
Capture data from real contributors in everyday environments.
02
Collect the messy, long-tail behaviors that labs and simulation miss.
03
Support collection with local operations, onboarding, and quality control.

Prototype → MVP → Product & CES showcase → Deployment
Execution Advantage
We are not starting from zero. The platform has already moved from prototype to product-ready deployment.
This gives us a faster path to execution than software-only approaches.
Privacy Layer
All captured footage is processed through privacy safeguards before annotation or downstream use.
Privacy is part of the infrastructure, not an afterthought.